 Accelerate
Accelerate Troubleshoot
Troubleshoot Observe
Observe
 A test is “flaky” whenever it can produce both “passing” and “failing” results for the same code. Test flakiness is a bit like having diabetes. It’s a chronic condition you can never fully cure and put behind you. Even if only 0.1% of your tests are flaky, with thousands of tests you can have problems with a considerable portion of your builds. This is common to even medium-sized development teams. Left unmanaged flaky tests can render a body (or body of tests) severely damaged. But your prognosis is good if you continually measure and act on the relevant health indicators.
A test is “flaky” whenever it can produce both “passing” and “failing” results for the same code. Test flakiness is a bit like having diabetes. It’s a chronic condition you can never fully cure and put behind you. Even if only 0.1% of your tests are flaky, with thousands of tests you can have problems with a considerable portion of your builds. This is common to even medium-sized development teams. Left unmanaged flaky tests can render a body (or body of tests) severely damaged. But your prognosis is good if you continually measure and act on the relevant health indicators.
When confronted with flaky tests, many organizations (including Gradle) implement an automatic retry when tests fail. This trades off increased build times for build reliability and test coverage retention. But this may allow the problem to fester and new flakiness to be introduced until one retry isn’t enough anymore. And then, where does it end? Two retries? Ten?
Some organizations give up and surrender to the problem and their test reports end up telling them almost as much about the quality and deliverability of their software as scrying tea leaves or consulting horoscopes.
Gradle reached a point where flaky tests were the number one developer complaint. A single automatic retry had been implemented, but it wasn’t enough anymore. The team did not want to sacrifice any more build time to additional retries and was wary that retries could be hiding real product problems. A perfectly correct, stable test covering flaky product code looks exactly like a flaky test and so real issues can easily be hidden by retries.
So Gradle configured its CI jobs such that any time a test fails once but passes on retry, an entry is made in a database that records the test and the time of the incident. After collecting data for a few weeks, it was analyzed to see which tests were causing the pain. Several hundred tests had at least one flaky failure, but a mere 10 tests were contributing 52% of all our flaky failures! Those tests were immediately disabled and issues were filed for the owners of those areas to investigate.
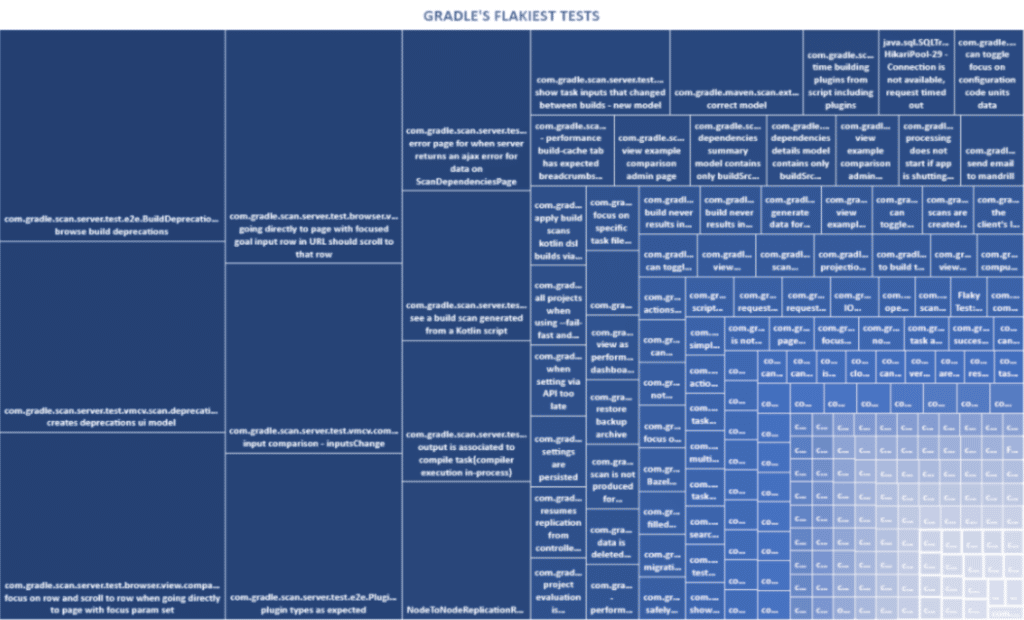
Figure 1: Each square is a flaky test. The bigger the square, the bigger the flake.
Reasonable engineers sometimes object to disabling flaky tests, worried that the disabled test will never be fixed, and its coverage lost forever. This anxiety can indicate a lack of trust that quality will be prioritized as part of the planning process. Setting aside the organizational pathologies it may signal, if the test is flaky enough that it can fail even when retried, you’ve already lost that coverage.
When flaky failures become a significant fraction of a test or test suite’s failures, engineers reasonably begin to assume that any new failure from that suite is spurious. They may cease to prioritize investigations and so the suite becomes useless, and bugs get shipped to customers that had been showing up red in test reports for weeks or months.
| A SUITE THAT DIED OF FLAKINESS
One company I worked at maintained a suite of roughly 10,000 browser tests for their server product and ran them nightly. These tests automated interactions with the web interface, which communicated with a fully running instance of the server. Since these were effectively end-to-end tests, problems anywhere in the product or infrastructure would substantially disrupt the results. On a good day the pass rate for this suite was 85%; on a bad day it could be as low as 55%. There were roughly 50 engineers responsible for this suite. Investigating and fixing a test is sometimes quick, but very often takes hours of work. To get the whole suite passing before the next nightly test pass, each engineer would have had to fix dozens of tests. With so many unreliable tests, and more being added all the time, doing anything about it came to feel Sisyphean. This suite passing was part of the process for merging work from the feature branch to the release branch we shipped from, a process enacted every two weeks. Some document somewhere probably said the suite was supposed to be passing before the integration happened. In practice, integration owners had to compare the results between the source and target branch to try and distinguish new failures from the thousands of existing failures. This process of trying to scry real results out of the suite was ineffective and mind-numbingly tedious, hated by everyone who got stuck participating in it. Bugs were routinely integrated that tests had accurately reported as failing. Legitimate failure signals were thoroughly drowned in an ocean of red, flaky failures. Digging ourselves out of that hole took a lot of time and effort that could have been spent on improving the product, had we not let the problem get out of hand in the first place. I still wonder about how many person-years were wasted. |
Measuring your blood sugar: Quantifying Flakiness
The pain test flakiness causes in an organization can be measured on an exponential scale. A little flakiness is barely noticeable. A lot of flakiness and your testing is rendered completely worthless, as any actionable signal is drowned out in a blood-red sea of noise.
So it follows that the ROI on fixing flakiness is logarithmic. Fixing the most-flaky test reduces pain substantially, but once flakiness is down to acceptable levels it becomes difficult to justify the opportunity cost of investing in flakiness fixing instead of new features. Therefore, an ongoing process is required to measure the severity of the problem in a way amenable to correctly prioritizing investments in time and resources.
So how much flakiness can you live with? The amount of flakiness you can tolerate is inversely proportional to the number of tests you have, the rate at which they flake, the number of builds you run, and how many times you retry on failure.
Flaky Failures/day = (Builds/day)(Count of Flaky Tests)(Chance a test flakes)^(1+retries)
Let’s say your organization has 200 flaky tests that run in 500 builds per day and you want no more than 1% of your builds, 5 in this example, to be disrupted by a flaky test failure. With no retries, you need to keep the average rate at which they flake under 0.005%. With a single retry, you can maintain a 1% flaky failure rate with an average test flakiness rate of under 0.7%. This means your tolerance for flakiness goes down as the number of flaky tests you have, or the number of builds you run, increases.
Common Sources of Flakiness
A test can be flaky for an unbounded number of reasons. Here are several reasons that may come into play across many different kinds of software projects.
- Accessing resources that are not strictly required
- Why is that unit test downloading a file? It’s a unit test. It should only interact with the unit under test.
- This includes accessing the real system clock. Prefer a mocked source of time controlled by the test.
- Insufficient isolation
- When running tests in parallel, resource contention or race conditions are possible if each test doesn’t get its own exclusive copy of the resource.
- Even with fully serial execution, tests that change system state may cause subsequent tests to fail if they don’t clean up after themselves or crash before cleanup has occurred.
- Tests interacting with a database should wrap all their interactions in a transaction that’s reverted at the end of the test.
- Asynchronous invocations left un-synchronized, or poorly synchronized
- Any fixed sleep period is a mistake if too short fails tests that would have passed; it is too long it pointlessly wastes your time.
- And “too short” and “too long” differ based on circumstances so no fixed value can ever be “just right”. Always poll the result with a reasonable timeout.
- Accessing systems or services that are themselves not perfectly stable
- Try writing most functional tests with mocked services. Use a smaller number of higher- level contract tests to ensure that the mocks meaningfully match the real service.
- Performance tests that can be highly variable, even when you try to control the circumstances in which they run
- Running the same scenario several times and discarding outliers can reduce noise at the cost of additional time and resources required to run the test.
- Usage of random number generation
- While obviously required for valuable techniques like fuzz testing, the random seed should always be logged and controllable otherwise reproducing any issues the tests uncover can be needlessly difficult.
- When re-running a failed test that uses random number generation, the same seed should always be used
Taking your Insulin: Keep flakiness under control
Since flaky tests pose a procedural challenge as well as a technical one, procedural adaptations must be part of the solution. Here’s an example process your organization could use you to keep the pain of flakiness tolerable and avoid having to write off whole test suites as a loss:
- Setup your CI to re-run failed tests a single time (unless there are more than 10 failures).
- Any test which fails then passes on re-run should be recorded, with a timestamp, as flaky in a database.
- Over the duration of a sprint, or whatever your planning cadence is, count how many builds you run total, how many fail due to flakiness, and how many flaky tests you have.
- Set a realistic tolerance threshold. If you have a million flaky tests you aren’t going to get to 0 in one go (except for the very largest codebases, it’s probably not worth the effort to de-flake a test that fails one in a million times).
- Disable any tests which flake at a rate above your tolerance threshold.
- File bugs for each test disabled and send them to the teams that own those tests. This is most effective if done in advance of sprint planning with notification of planners.
- A test should not be allowed to be re-enabled until the supposedly fixed version has been run enough times to demonstrate that it flakes at a rate that doesn’t threaten your tolerance threshold (a special CI configuration).
- Repeat this process on a regular cadence.
- Periodically check for tests that have been disabled for a very long time without being re-enabled and consider additional notifications or escalations.
If performed completely manually, this can be a lot of work! Fortunately, many of these steps are highly susceptible to automation. After the CI jobs are in place, identifying flaky tests and filing bugs accordingly can be automated. Automatically disabling tests is harder, but still achievable with a script that knows how to perform and commit an abstract syntax tree transformation.
Prognosis
Hopefully, I’ve provided some useful educational information about the importance of properly diagnosing and treating flakiness and best practices for managing this malady. As I indicated immediately above, the next step is to leverage automation. I recommend you learn more about the flaky test management capabilities available in Develocity which supports both Gradle and Maven builds.