 Accelerate
Accelerate Troubleshoot
Troubleshoot Observe
Observe

The more quality matters to an organization, and the more tests they have, the more likely it is that some of these tests will be “flaky”. What is a flaky test? A flaky (or intermittent or non-deterministic) test is a test that—given the same code, the same inputs, and the same environment—sometimes passes and sometimes fails. I’ve written before about why we shouldn’t ignore flaky tests. During one DevProdEng Showdown, Rooz Mohazzabi asked Developer Productivity experts at four large financial organizations—U.S. Bank, Goldman Sachs, Morgan Stanley, and JPMorgan Chase—about how they address flaky tests. They agreed that the most effective way to address flakiness in a test suite is “a combination of mechanisms and mindset change.” In this post, we’ll explore both.

How Top Banks Deal with Flaky Tests – Excerpt from the DevProdEng Showdown
Watch DevProd experts from top banking institutions discuss flaky tests in this DPE Showdown
What sort of organizational culture addresses flaky tests?
You run your builds regularly, have tools in your CI that help you detect these flaky tests, and provide guidelines to your engineers so they can debug and fix them soon.
– Ankhuri Dubey
Teams should be encouraged to run their test suite frequently and use tooling and automation not only to do this but also to identify flaky tests. This ensures an engineering approach to quality rather than depending upon individuals or other teams to flag potential problems. But that’s just step one. It’s just as important to define what to do when flaky tests are identified and make sure all the individuals and teams involved are aligned:
- When should it be fixed?
- Who is responsible for fixing the test?
- What are the common causes of intermittency?
- Are there tools or approaches you can use to debug flaky tests?
- What do you do if the test cannot be fixed in a reasonable timeframe?
In order to identify, prioritise, and troubleshoot flaky tests and to figure out the answers to some of the above questions, the organization needs to gather data to see what’s really happening and so understand how much of a problem flaky tests might be causing.

For this particular problem, data is key. Investing time in keeping track of the previous and historic runs helps you understand where tests are flaky. This allows you then to perhaps prioritize those tests on subsequent runs so you can get faster feedback cycles and fail earlier.
– Robert Keith
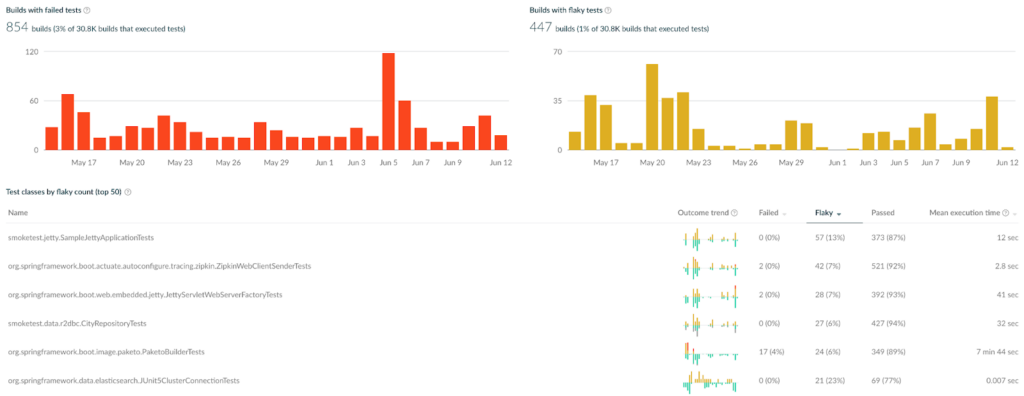
Develocity’s flaky test detection
In addition to all of the above, you’ll also want to build a culture which focuses on the prevention of flaky tests, so you spend less time fire-fighting flaky tests and concentrate more on the quality of the tests being written in the first place.

Get the team [to] understand that they’re accountable for the outcome of what the test was meant to accomplish. DevOps practices were what started this at my previous company, helping the engineers be empathetic to the outcome, the operations of their products.
– Levi Geinert
When do you fix flaky tests?
The first appearance of a flaky test is the best moment to fix it. That’s the guiding line for us.
– Ankhuri Dubey
The best time to fix a flaky test is as soon as it appears. Whether it’s a new test that has somehow been written or run in a way that invites flakiness, or an existing test that suddenly becomes flaky, the best time to debug this problem is when the flakiness appears. This way, you can identify what may have changed to create flakiness in an existing test or look closely at a new test to see if it uses known patterns that invite flakiness.

I completely agree that flaky tests cut the queue [so they get fixed first]. Fighting flaky tests on release day is just brutal, a total waste of time.
– Eric Wasserman
Who’s responsible for fixing flaky tests?

Keep it close to the team and don’t have it as a separate function.
– Levi Geinert
The overall consensus is that it’s the application developers who should be fixing flaky tests as soon as they are introduced. They know the expected behavior of the code, and they should be close to any changes that might have introduced flakiness. However, if there’s a backlog of flaky tests that need to be addressed, these can sometimes be ignored by the development team in favor of current priorities. One way to ensure that you fix flaky tests without a current owner is to create a team of specialists focused on fixing flaky tests.
Have an internally rotating micro-team of ninjas to attack this stuff as early as possible.
– Eric Wasserman
We’ve also used janitor teams to go after that backlog [of flaky tests].
– Robert Keith
How do you avoid creating flaky tests?
The reality is you have to create a culture of test-driven development. Test first, get the team thinking about what a successful outcome would be, and test for that.
– Levi Geinert
Developers need to consider the desired outcomes of the tests, perhaps even before writing the tests, as a way to ensure both that the tests are testing the right thing and that they are testing it correctly. Your development team should treat tests as first-class citizens and give test code the same respect as production code. Tooling can also help here by identifying poorly written tests.
Leverage tooling like quality scans, and extend it to scan for code smells. There are lots of bad smells in tests like sleep() that help you identify flaky tests before they even get executed. You can quarantine those kinds of things and feed them back into the backlog for resolution.
– Robert Keith
It’s not just about writing clear code in the tests—it’s also about selecting the correct way to test a specific behaviour and test it at the correct level. The testing pyramid is one way to consider the types of tests being written and maintained. Longer-running (and usually less reliable) tests are towards the top of the pyramid, faster and more reliable tests towards the bottom.
There’s a temptation to write integration and end-to-end tests, as it can be easier to reason about the expected behavior. However, you get faster and more reliable feedback from unit (including sociable unit) tests and tests that do not require integration with other technologies or services. Often, you’ll find that slower and less reliable end-to-end tests can be re-written as one or more faster-running tests that give you quicker, more reliable feedback.
There’s just too much reliance, I think, on integration and end-to-end testing right now, which lends itself to flakiness. So focus more on the base layers of the testing pyramid.
– Eric Wasserman
And finally… how do you fix flaky tests?
I’ve written about the common causes of non-deterministic tests before. A couple of these were mentioned in passing, specifically “non-determinism by poorly written tests” and “the build infra”, and one suggested solution for decreasing test flakiness is “improved reliability of test environments”.
A word of warning:
You don’t want to be in a place where your engineers think that retrying is the way to fix flaky tests.
– Ankhuri Dubey
Retries can be a mechanism for identifying flaky tests, but re-running tests multiple times is not only not a fix but increases the time and cost of your CI environment.
The importance of mindset
My previous posts explore a number of approaches to identifying, prioritizing, and fixing flaky tests. The solutions include automation, tooling, and process—which could all be considered “mechanisms” for dealing with flaky tests. But there are also questions of “when”, “how”, and “who”. Where do the responsibilities lie for reducing failures due to flaky tests? This is the mindset discussed in this post, a mindset every team or organization needs for effectively tackling the problem.
I shall leave you with one final quote of wisdom:
Mechanisms, I would say, are more straightforward.
Mindset, I would say, is the harder part to achieve.
– Ankhuri Dubey